







Nowadays when people hear ‘microservices’ they often think about the benefits that come with the architecture but neglect some of its inherent risks. Indeed, microservices applications can present unique problems, many of which may be even more difficult to trace and troubleshoot than in traditional setups.
In this blog post, we will cover an overview of common issues and challenges when working with microservices architecture. We’ll take a look at potential solutions for troubleshooting and the ways to address these challenges, such as handling transient errors, implementing asynchronous communication, ensuring microservice resiliency, versioning, logging, and distributed tracing.
Microservices and the most common type of errors
Microservices refer to an architectural approach where software applications are broken down into small, loosely coupled, and independently deployable services that communicate with each other over a network. Each microservice is responsible for specific functionality and can be developed and deployed independently. The architecture comes with a lot of benefits such as better testing and high availability, but troubleshooting and identifying а problem can be problematic. When it comes to distributed applications there are a couple of risks we should consider:
Transient Errors
Transient errors are errors that occur for a short period of time. There is the risk of partial failures because of outages in the cloud, bad implementation, or too many requests which may result in unavailability as well. For example, when the database you are trying to access is being transferred to a different server on the cloud it becomes unavailable for a few seconds. Thus, you should try to design your application to tolerate faults within reason, as even small downtimes can be disruptive.
Common solutions:
- Asynchronous communication.
- Retries with exponential back off.
- Limit the number of queued requests.
- Provide a set of rules and what to return when a failure occurs.
Non-Transient Errors
Non-Transient errors refer to the more traditional concept of bugs and defects. These are persistent errors that continue to occur if not fixed, and should therefore be addressed accordingly.
Microservice resiliency
Microservice resiliency is essential for maintaining the availability and reliability of microservices, particularly in the event of temporary database unavailability. One effective solution is to implement ‘Retries with exponential back off’ for internal communication using HTTP polling. Furthermore, adopting practices such as asynchronous event-driven communication, eventual consistency, and utilizing the outbox pattern can help mitigate issues of data inconsistency between microservices. Additionally, health monitoring and versioning practices play a crucial role in ensuring the robustness and stability of microservices, while logging solutions like ELK stack, Azure Diagnostics, and others facilitate effective debugging and issue resolution.
Here are some of the key strategies and best practices that can be implemented to address common errors in microservice communication and enhance the overall resilience and reliability of microservices:
Asynchronous event-driven communication
Bounded contexts are boundaries where the domain model operates. They can mean different things to different microservices, so when a change occurs, you need some way to reconcile changes across the various models. А solution to this problem is eventual consistency and event-driven communication. When we use asynchronous communication based on asynchronous messaging, the data could be inconsistent due to completely or partially failed messages.
As shown in the diagram below, when a change occurs, the microservice must publish an event while another microservice needs to be aware of it to keep the data consistent between them both. The publish/subscribe implements an event bus. The additional microservice subscribes to an event to receive the message asynchronously. In this scenario, the user-profile microservice updates the user, publishes a new event, and then the information about the buyer is updated (the user is referred to as a buyer in the domain of the basket and ordering microservice).
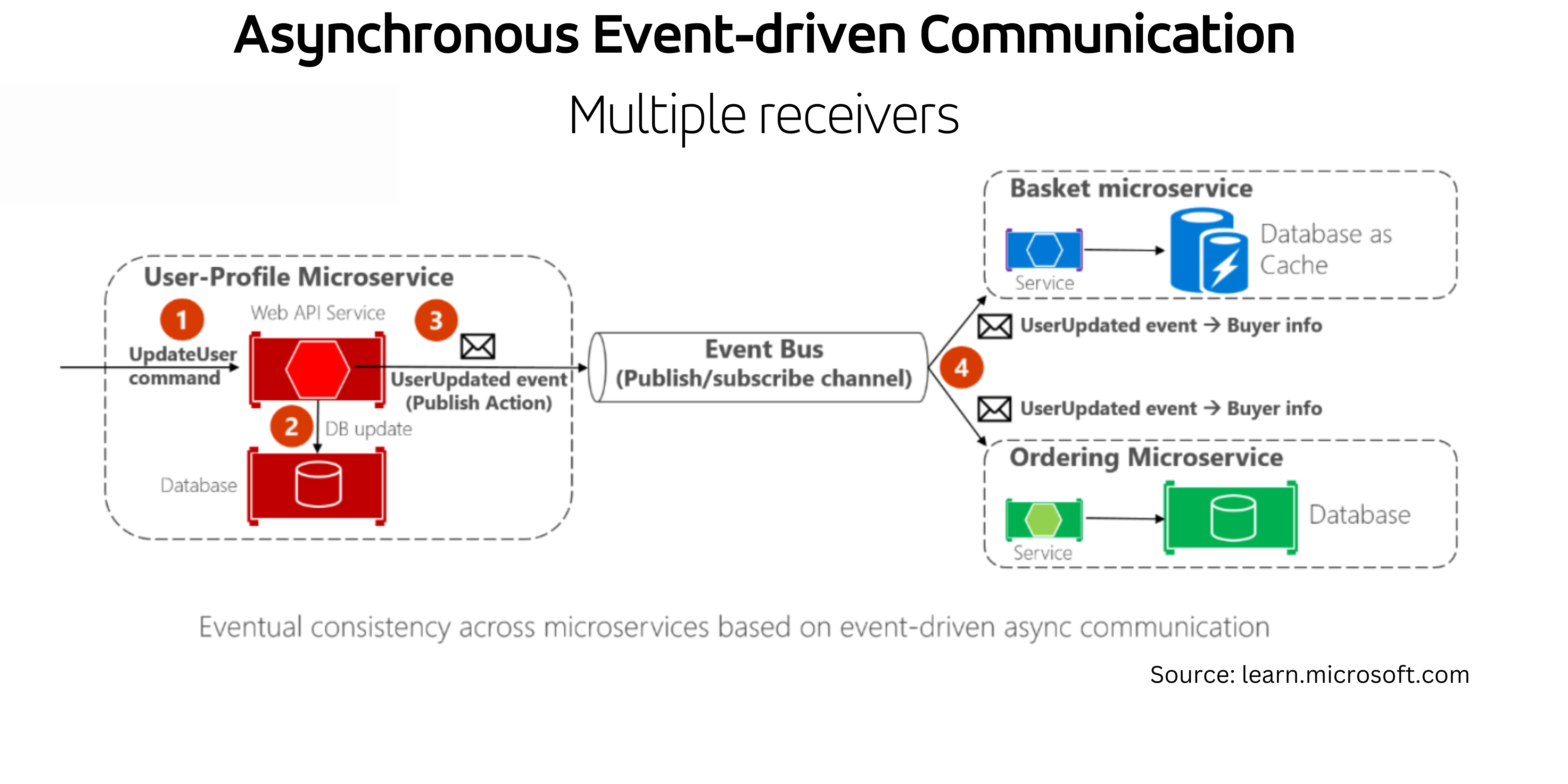
The partial failures might lead to inconsistency in the data between the microservices. That’s where the outbox pattern comes to help. We store our messages and mark them as ‘Pending’ or ‘Completed’. Before publishing the event, the message is marked as ‘Pending’ in the database transaction. Once it’successfully processed, we update it as ‘Completed’ in the new database transaction. It is good practice to have a background job to check periodically for failed messages (marked as ‘Pending’ but never processed) and publish them once again. This method guarantees us eventual consistency. Additionally, the receiver microservice should recognize duplicated messages and discard them. Using GUIDs when adding a new event to the EventLog table is a good method to distinguish identical messages based on the message data.
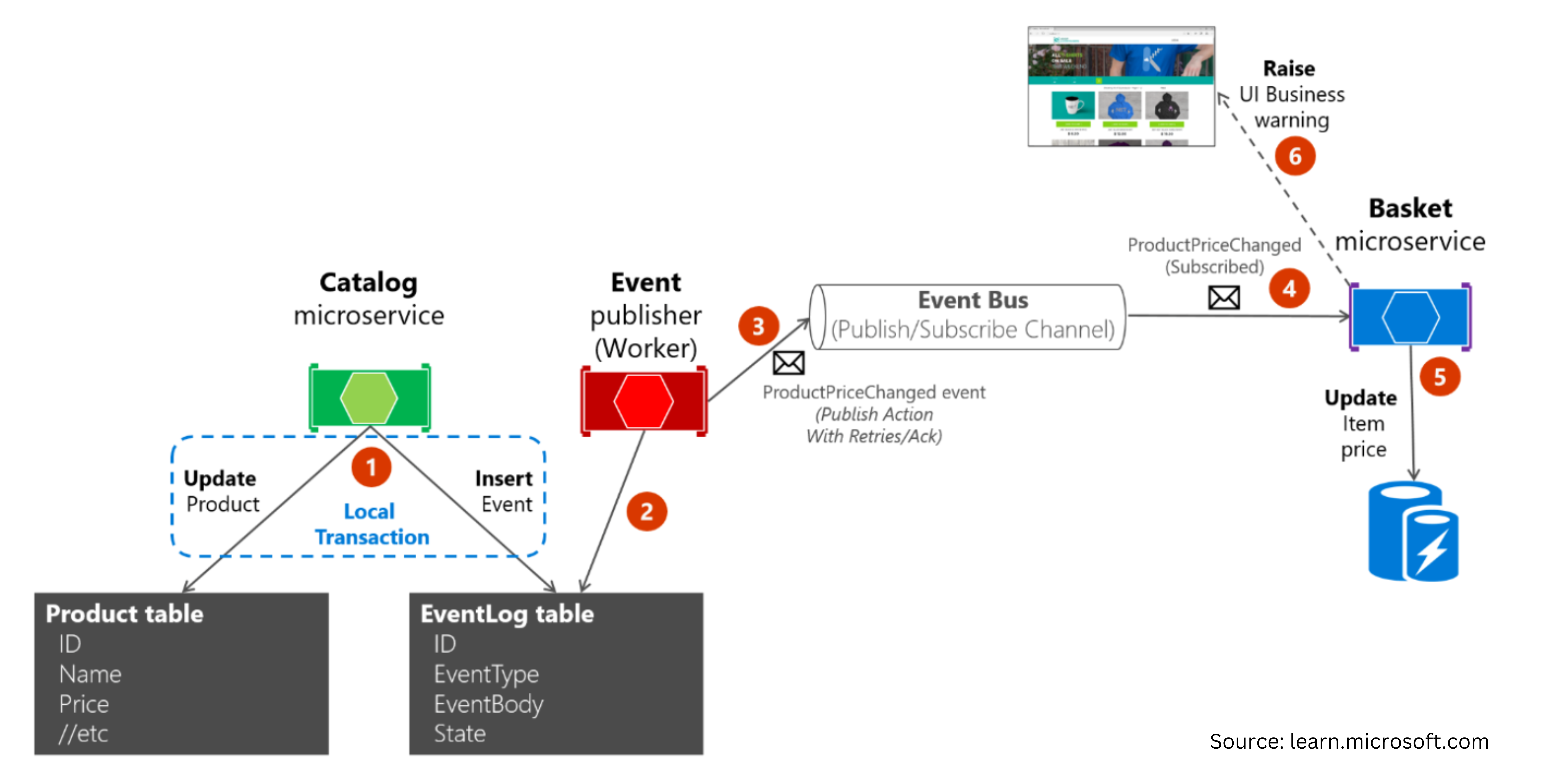
As described in the graphic above, the catalog service creates a transaction for updating a product and its price and creates a new Event in the EventLog table. The worker then checks the table for the latest events and publishes it to the event bus. The basket microservice receives the new update and updates the price of the according product in its database then the user interface is updated.
Resilient Messaging in Microservices: Accedia Success Story
For example, at Accedia there was a project in which we had problems with the asynchronous communication, and we solved the issue in a noteworthy way. For explanation purposes, we will call the microservices which communicate with each other ‘A’ and ‘B’. The first one (referred to as A) is the sender, and the second one (referred to as B) is the receiver. When a specific email is received in one mailbox, A sends data from that email to B via an event bus. For a long time, this has been a significant bottleneck for B, as its business logic depends on several other services. If one of them fails, the message is sent to a dead-letter queue. We implemented two types of strategies to help reduce “lost” messages: 1st level retry, and 2nd level retry.
1st level retry takes care of immediate failures, meaning that if a message fails, it is immediately retried X number of times. If it fails X times, the message is deferred. This is where the 2nd level retries come in. The deferral is stored at the database level where there is a table for deferred messages. It stores the body of the message when it should be retried, and some metadata. At a certain configurable period of time (e.g. 1 or 2 seconds), the database is checked for any messages whose retry time has arrived. If there are any, they are retried as completely new messages, going through all the retries again, and so on.
The interesting part here is that the circle is closed – there is no way for a message to be lost. We defer them “exponentially”. For example, the first time a message fails X times in 1st level, we defer it for 5 minutes (i.e. it will be retried after 5 minutes), the second time for 30 minutes, the third time for 1 hour, the fourth time for 6 hours, and so on (this depends on the case and configuration). The idea is that within 6 hours, we will have enough time to fix the bug if it is not severe.
ELASTICSEARCH AGGREGATIONS: GETTING STARTED
Health monitoring
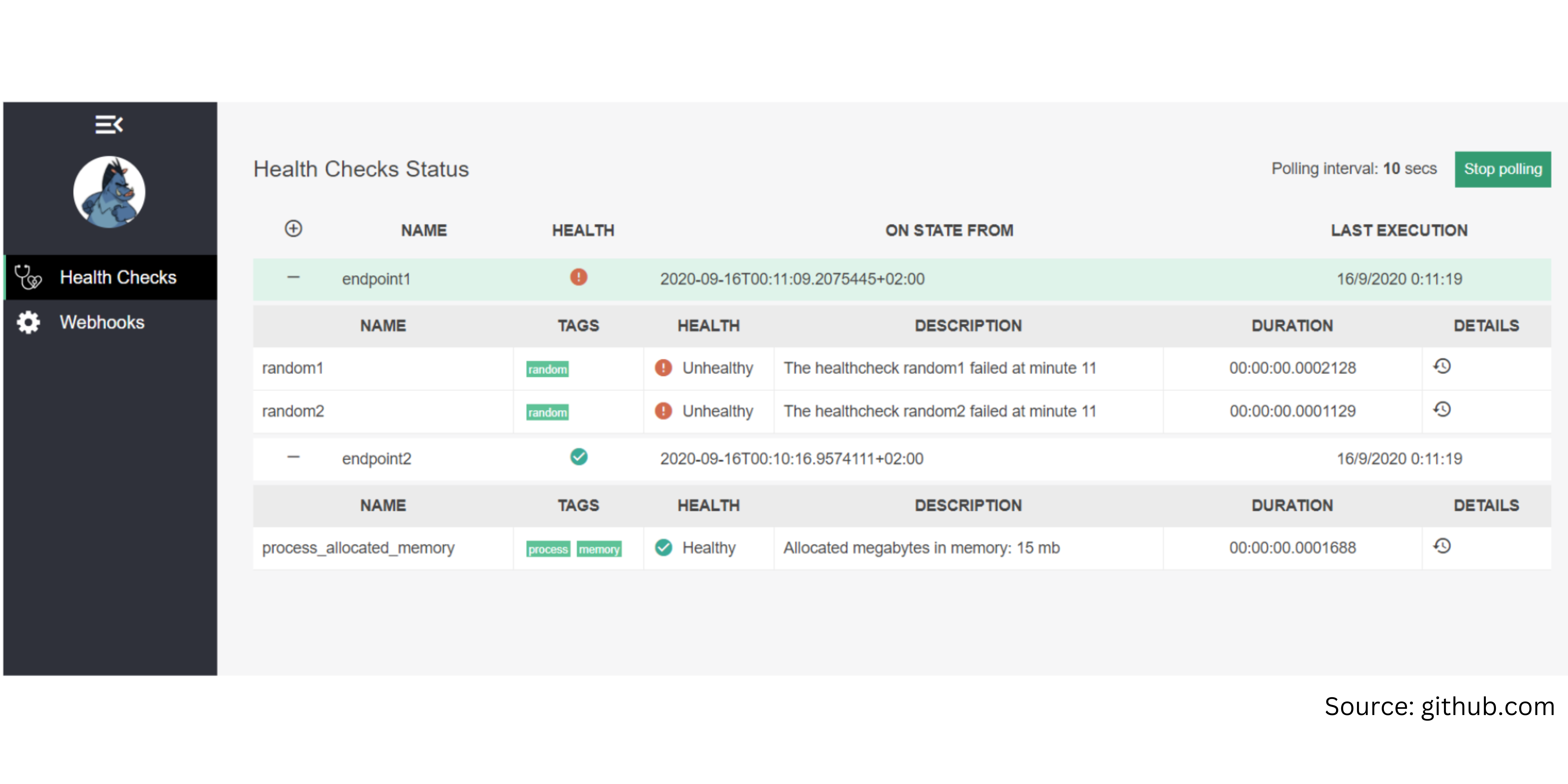
Health monitoring allows almost real-time information about the state of our containers and microservices. For example, AspNetCore.HealthChecks.UI Nuget package provides an interactive UI for health checks status for your microservices/containers.
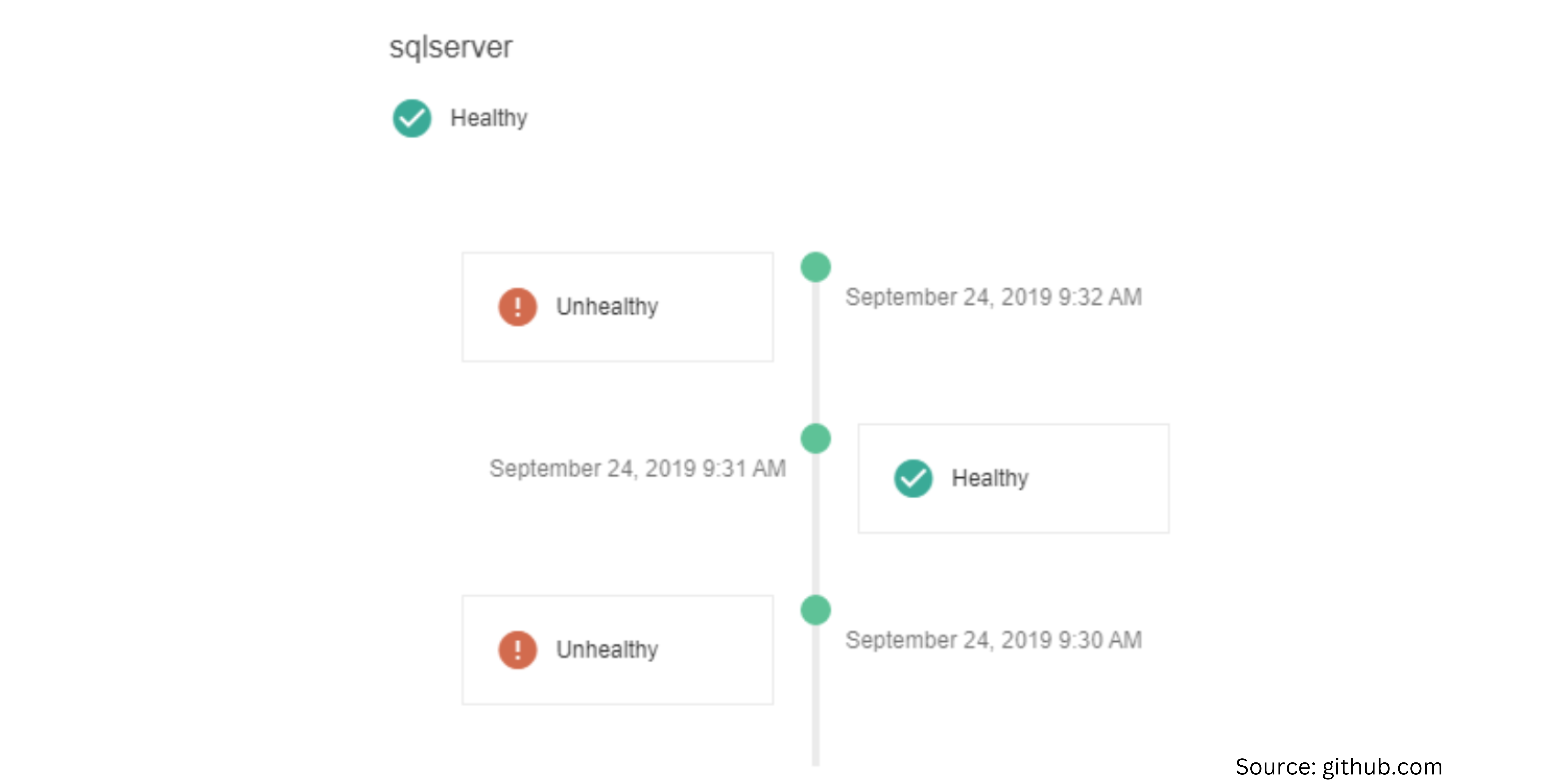
As well as health status history timeline:
Versioning
Typically, microservices are deployed independently and that’s one of their benefits, which means that an API can break client applications. That’s why it is a good practice to implement versioning when you introduce a breaking change that may affect the client and cause their application to fail. The old and new API versions should be live at the same time to make sure the clients work correctly. Just a change in the request/response format of the contract can be considered a breaking change – e.g. removing a property from the response or changing a parameter name from ‘name’ to ‘username’ or vice versa.
Logging
There are six levels of logging – Trace, Debug, Info, Warn, Error, and Fatal. Each name gives you a hint of what they are about. Logging in the microservice application should be more central-oriented. Each separate application should write its log files. To effectively debug a microservice architecture, it is essential to overcome the challenges posed by obfuscation and complexity. One way to achieve this is by ensuring that the logs are robust and high-performing and can be filtered and searched for information. They should be collected and aggregated by the infrastructure. Setting up alerts can help us to get notified when a fatal error occurs.
Common solutions
- ELK stack (Elastic search, Logstash, Kibana)
- Azure Diagnostics
- Google cloud logging
- Graylog
- Splunk
ACCEDIA SOLUTION ARCHITECTURE SERVICES
Distributed tracing
Distributed tracing pertains to techniques for monitoring requests as they traverse across distributed systems. It is a technique that reveals how a set of services fit together to handle individual user requests. With distributed tracing, you can reduce the mean time to detect and repair.

Common Solutions
- Correlation ID. A common solution is adding a Correlation ID. It is a unique, randomly generated identifier that is added to every request/response. When you are making a new request to a different microservice, a correlation ID is attached to the request/response. Having the correlation ID provides a great way to filter the logs using it.
- OpenTracing is another common solution. Jaeger is a widely recognized implementation of OpenTracing, while Squash enables runtime debugging on distributed applications and seamlessly integrates with IDEs. It facilitates live debugging across multiple microservices, enables debugging of containers in a pod, allows setting breakpoints, as well as viewing and modifying variable values, and so on.
To wrap up
Microservices are a great approach to simplify complex business cases in terms of development. However, we should take into consideration a lot of potential problems and implement our system to be fault tolerant and resilient to extract the maximum benefit out of it.
If you have any questions about using microservice architecture in your project and how to benefit from it, please let me know and we can have a chat.